


10月26日-27日,2018易观A10大数据应用峰会在北京如期召开,本次峰会以“数造未来 精益成长”为主题。来自国内外的大数据实践者、资本掌舵人、企业家、技术大咖、运营专家、应用开发者以及知名媒体人齐聚一堂,共同讨论和分享在数据驱动下的企业精益成长之道。

在10月27日上午举行的易观A10峰会数造未来主论坛上,易观CTO郭炜做了题为《流动水系数造未来》的主题演讲,郭炜在演讲中以自身丰富的技术从业经验,为我们分享大数据下的数据难题以及应对方法。以下为其演讲实录:
对于大数据,企业经常会遇到这样的问题:大数据大而不强、人工智能人工而不智能。为什么这么讲?过去我们在做大数据时,经常把企业认为有价值的数据都存在一起,但当我们使用的时候,会发现随着数据的沉积,越来越难以使用这些数据,为什么呢?因为随着时间的流逝,数据的定义、数据的格式、业务的含义已经逐渐都发生变化,越来越不清晰。随着时间的变化,我们的数据湖(Data Lake)最终变成了一片数据沼泽。
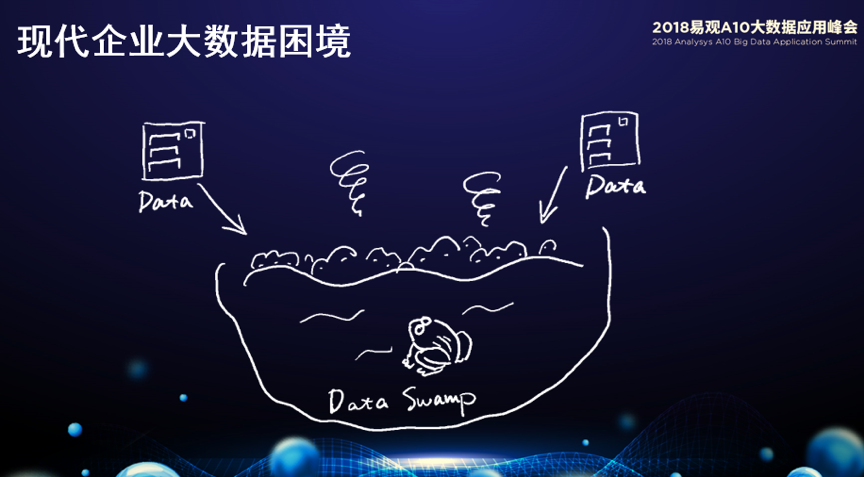
我相信很多企业都会遇到这样的问题,于是有些企业开始做大数据治理。但真正数据治理非常困难,这是为什么呢?因为长时间积累下来的数据,每次规整和删除都非常痛苦,不知道哪个业务部门在使用它,不知道它真正的含义,或者将来是不是可以用到它。
每一次CTO和CIO都会遇到这个问题,大数据的价值究竟在哪?感觉自己的大数据团队人员永远不足;感觉大数据存储永远不够;数据永远难以满足业务分析维度,还有不统一的数据标准融入等等一系列问题。
当然易观也遇到这样的问题,易观SDK月活接近5.9个亿,约6.8PB的数据存储,目前我们已经存储到了90%。当我找老板要服务器,跟老板汇报说:“我们6.8PB数据已经存满,现在只能存储不到一年数据,我们需要更多的存储”,老板问,“这些数据在哪里使用,有什么用?”而我还继续说,“下一步物联网数据要来了,IOT数据的量级是我们现在移动互联网量级的10倍,还要多10倍的存储”。老板睁大眼睛问我说,“郭炜啊,你觉得我们这些数据的价值在哪里?” 这是我们每一个CTO或者大数据总监去跟老板要资源的时候都会遇到的问题,那么我们该怎么解决这个问题?
答案就是我们要给企业做一个数据驱动的中台。很多企业都知道数据中台的概念,认为数据中台就是把各种数据组件打包、把大数据存储好即可。但是这样做随着时间积累,数据中台就会从数据湖变成数据沼泽。怎么办呢?我们的理论是提出一个数据河的概念。中国有句俗话叫“流水不腐,户枢不蠹”,就是数据一定像河水一样流动起来,才不会产生瘀泥。

那数据河的概念是什么?数据河就是从数据产生端直接通过IOTA数据河实时流向数据使用者。这样有个好处,每一个数据的发生者都会有一个使用者,而不是大家想象中说这个数据很有用,但数据谁用了我不知道,只是单纯把它存储下来。
这样做,会带来什么好处呢?数据的每一次产生和使用都是确定的,是否要存留是根据我们数据使用者的情况去做的。大家都在讨论数据治理,这其实是一件非常痛苦的事。在10年前,我在IBM给一个数据银行做数据治理,那个项目当时耗费了两年多时间,数据治理是件很复杂的事。但当我们变成数据河以后,我们可以通过飞轮驱动效应来实现大数据治理。
什么叫飞轮驱动效应?这个名词来自于亚马逊,意味着一个东西在转起来的时候是自己驱动自己在加速运转。数据的使用者特别关注最后数据产生时的样子,所以当你的河水发生污染,里面数据质量不好的时候,不用担心最后变成瘀泥的时候再治理会很难。你的数据使用者会第一时间告诉你:对不起,我们的数据有问题。

当把数据河放到整个企业的时候就会形成数据水生态。并不是说一个企业自己一条河流或者一个水系就能把所有的河都治理好。大数据是开放的,是要流动的。所以我们在外部会有第三方合作伙伴,他们会把一些数据实时灌注到企业里,帮助把企业里的数据水系扩充得更好。
再说说什么是IOTA架构?大数据IOTA架构是易观今年年初提出的。我们所提倡的大数据不是存下来,而是实时流动起来的。它分为几部分,边缘计算的SDK,统一数据模型,云端存储于计算引擎。
IOTA架构可以归纳以下4个特点:去ETL架构;边缘SDK计算;非结构化实时转化结构化数据存储;支持IOT设备。

大家过去在做大数据计算的时候,都要把它放到云端,放到一个平台里面去算,但随着我们手机端越来越强大,大家发现其实现在的手机可能就像5年前的电脑一样强大。为什么我们还要把所有的数据放到云端去算?IOTA架构给了大家一个答案,我们的数据其实在数据产生的时候就边缘SDK计算了,在云端时只负责存储和查询。
而统一数据模型,就是IOTA架构下自始至终从云端、计算端到最后使用端都是一套数据模型。 我举一个大家在做用户行为分析时会使用的模型,叫做主谓宾模型:就是谁、什么时间、在哪、干了什么。比如,过去看移动端用户行为数据的时候,很简单,某一个用户的ID在这个页面点击了这个按纽;而IOT时代,智能wifi去采集的时候也是一样这个模型——可以看到用户的MAC地址什么时间出现在哪一个楼层;对于人脸摄像头来讲也是如此,人脸的特征什么时间进入某一个汽车站。同样你会发现,在过去做各种各样数据采集的时候,每一次都要在云端做ETL复杂的事情,而IOTA架构把数据分散在数据产生端,就可以去解决在云端处理时的各种复杂情况。
当然IOTA架构也有它的缺点,就像我们前面提到,一个IOTA架构的数据河只能处理一个主题域的数据,比如说用户行为的统一数据模型,对于另一个主题域我们会有另外一条IOTA的数据河让它去处理,例如产品消费和库存。
IOTA架构的好处就是在数据的产生端,直接实时传送给最后的用户行为分析人员去使用,而不是把它沉寂下来再看怎么去做,这样直接提高了我们整个大数据的使用效率,实现了数据驱动的业务闭环。
易观自己基于IOTA架构开发了一个实例,叫做易观秒算,由底层边缘的SDK到相关的数据接入子模块,到查询引擎支持前端应用,目前已经在易观方舟ark.analysys.cn产品中使用。而昨天发布的企业成长版易观方舟就是基于企业生态水系实现营销闭环的数据平台,它既有能采集到企业内部的各种不同数据的SDK(手机端、小程序、H5、Java、Python等),也支持易观或第三方任何一家的外部数据增补,还可以对接企业内部的ERP、CRM数据。而底层的秒算引擎提供让BI和大数据人员二次开发的SQL接口,以便企业精细化运营闭环的各种分析和使用。
对于易观方舟ark.analysys.cn来讲,我们提供的是一个PAAS平台,就像我们刚才说的数据生态一样,我们不认为易观一家就可以把这个平台做好。所以易观怀着非常开放的心态愿意和大家合作。那么易观能给大家提供什么呢?
易观经过18年的积累,已经有三千多家企业客户,我们愿意和大家一起共享资源。
易观有丰富的数据资源,每个月月活5.9亿设备的数据资源。希望有更多算法公司或者个人开发者加盟到联盟中,一起利用好这些数据。
易观有IOTA架构的方舟PAAS,大家可以在上面开发自己的组件,易观将帮助你们把这些组件打包卖给客户实现盈利。
当然,我们也有深入行业的各种业务分析场景。无论你是企业还是开发者,我们都可以提供多种场景帮助大家解决相关商业问题,与大家共同推进国内大数据生态发展。
在这,我也代表易观,期待更多大数据开发者和企业加盟,给国内外企业提供更好的大数据服务。谢谢各位!
