易观分析发布《2025年AI产业发展十大趋势》报告,后续将针对十大趋势分别进行解析:

趋势之一:self-play RL范式开启,大模型技术军备赛进入复杂推理阶段
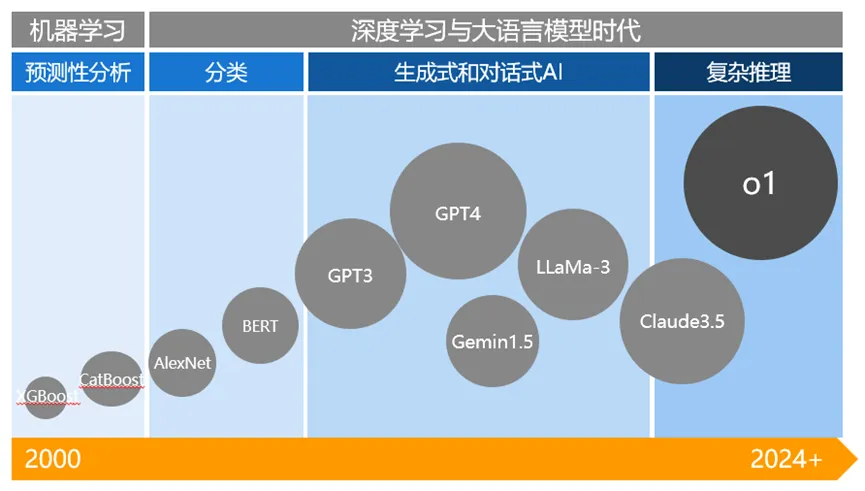
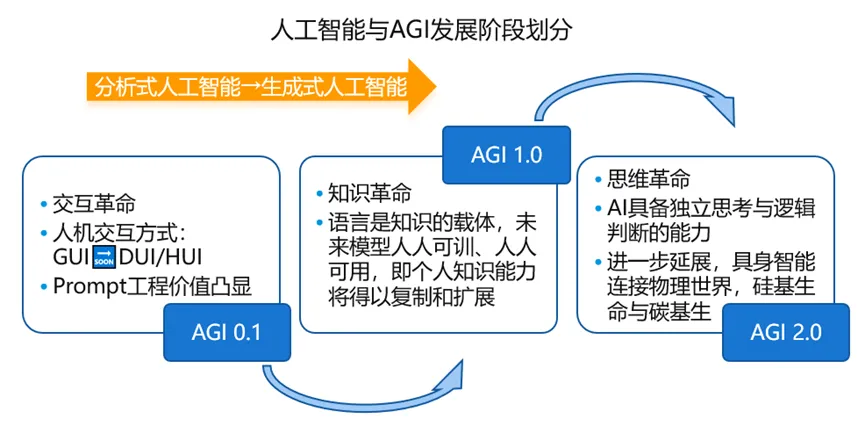
由OpenAI发布的GPT3作为序幕,大语言模型理解和生成能力、通用和泛化能力提升等,引爆了对于AGI发展的高预期,大量大模型涌现,开源模型与闭源模型并驾齐驱,国内大模型也在奋起直追,人工智能的发展从分析式AI进入生成式AI时代。
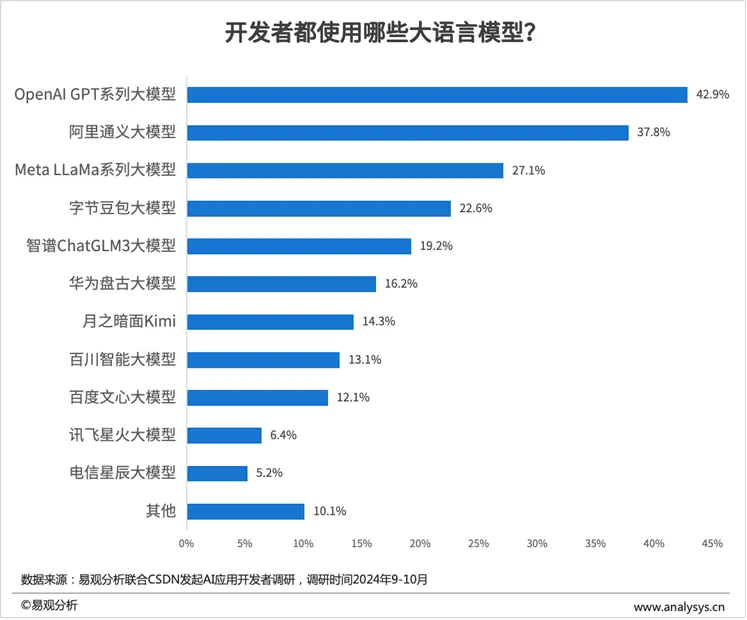
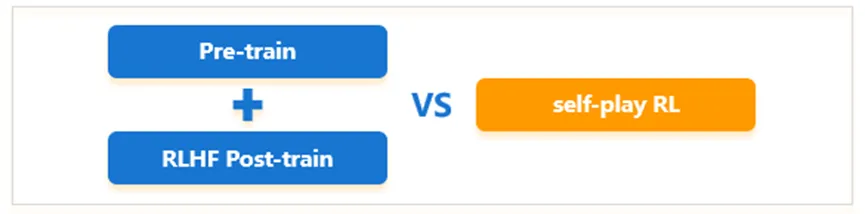
通过易观分析AI开发者调研结果来看,OpenAI GPT系列大模型以42.9%的使用率位居首位,同为海外的Meta LLaMa系列大模型以27.1%的比例位居第三位。中国的大模型企业,阿里通义大模型以37.8%的使用率位居第二。总体上而言,AI开发者在模型层的选型仍然处于变动的状态,且尚未形成相对比较明确的竞争格局。而OpenAI发布o1(草莓)模型,则再次定义大语言模型的技术方向与竞争焦点,如下图所示:与以往的模型相比,OpenAI o1 聚焦于优化推理过程,在复杂的科学、编程和数学等任务中的表现显著提升。它能够像人类一样进行深入思考、逐步推导,这对于解决需要深度逻辑推理的问题具有重大意义,突破了对大型语言模型能力的传统认知,为人工智能在复杂任务处理上开辟了新的道路。由此而开启Post-train阶段的Self-play RL(自对弈强化学习)范式对于后续大模型技术路线的升级和优化具有指引性的意义,传统预训练依赖全网语料,数据有噪声且质量不一,RLHF 后训练受人类标注数据限制。纯强化学习(RL)方法无需人类标注数据,能让模型自我探索学习,激发创新和探索能力,利于突破未知领域。
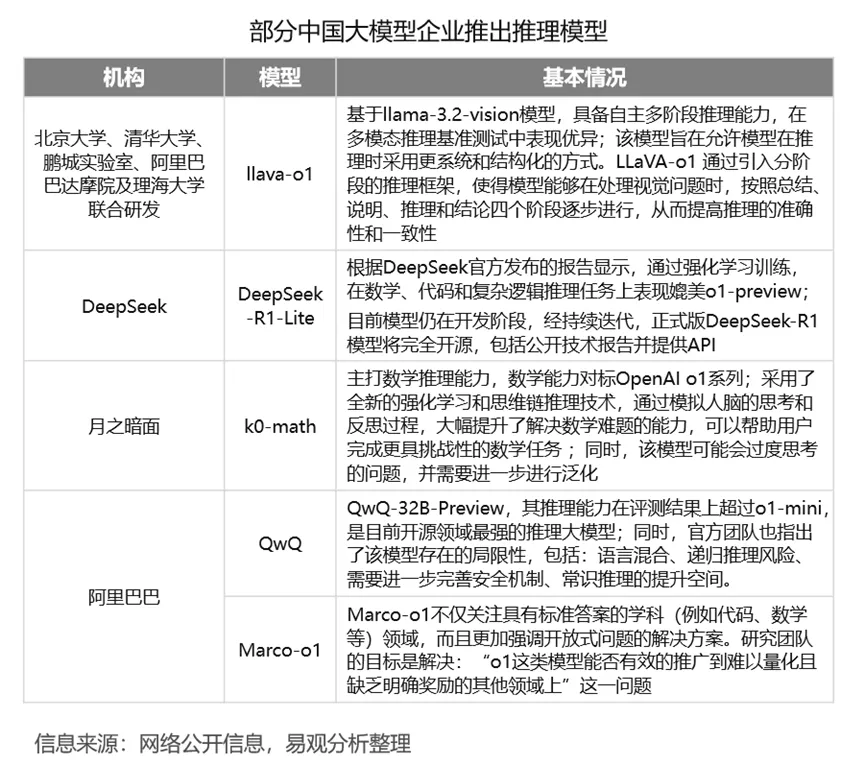
同时,也需要注意到,尽管Self-play 方法已经开始在一定范围内得到应用,但是,也仍然存在挑战需要进一步研究和解决,包括收敛性问题、环境非平稳性问题、可扩展性与训练效率等问题。另外,强化学习注重设计良好的“奖励模型”,但是除了数学、代码等理科领域,强化学习在其他领域仍然难以泛化。在OpenAI发布O1推理模型之后,国内大模型厂商也紧随其后,纷纷推出了自己的推理模型。这些模型在数学、代码、推理谜题等多种复杂推理任务上取得了显著进步。总体上而言,在复杂推理阶段,大模型需要具备更高层次的逻辑推理、因果推断和问题解决能力,进而可以扩展大模型在更多领域发挥重要作用,复杂推理的重要性凸显。这进一步提升了当下大模型技术能力的评价标准与竞争壁垒。